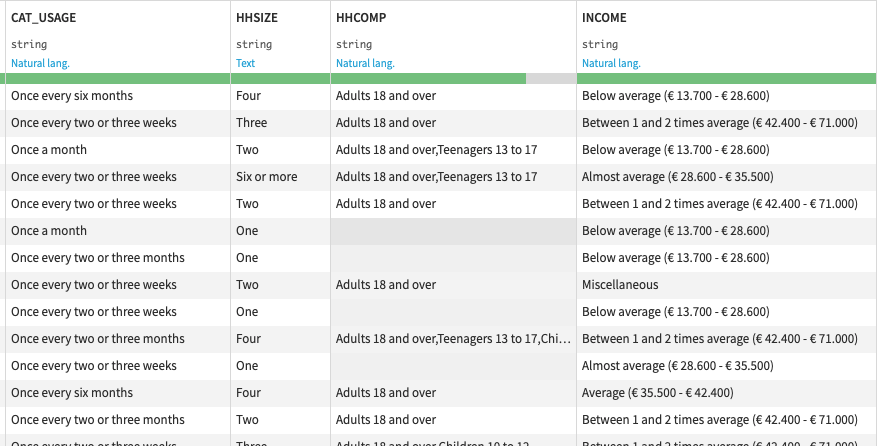
Decoding questionnaire
This is an example of mapping different values in the results of an encoded questionnaire (4237 rows and 194 columns). In stead of the actualy brand name it only states brand_0014 for example. Also, the answers based on some scale only has numbers where we for example want “Adults over 18”, “Teenagers”, etc. in stead.
This could have been done with Dataiku as well using a simple “Find and replace” function, however it would have been much more complex and time consuming, as you would have had to do it one column at the time. Using Python we can easily loop over each column and do the mapping efficiently.
Below you can see a couple of screenshots of the encoded data set:
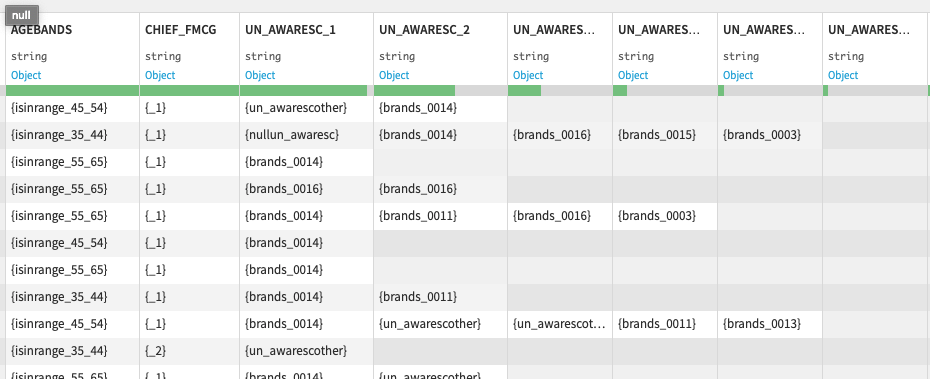
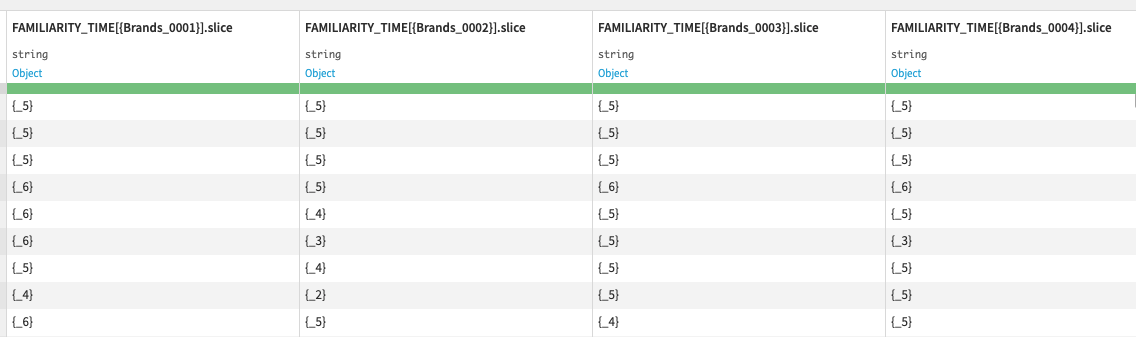
First I perform a couple of simple replacements on a some of the the columns refering to the first standard questions. Also, I remove all the curly brackets from the dataset. I also want to remove the underscores, but that has to be done after the mapping of the brand names.
df_map.replace({'{':'', '}':''}, regex=True, inplace=True)
df_map.replace({'_':''}, regex=True, inplace=True)
df_map['SEX'].replace({'_1':'Male', '_2':'Female'}, regex=True, inplace=True)
df_map['AGEBANDS'].replace({'isinrange_':''}, regex=True, inplace=True)
df_map['CHIEF_FMCG'].replace({'_1':'Almost all the time', '_2':'Half or more than half the time'}, regex=True, inplace=True)
Next I create a dictionary determining how the brand codes should be mapped. This could also have been stored in a seperate mapping dataset, but it was ok to solve the problem like this in this case. The dictionary is reality bigger than the example below, but this is to keep business sensitive data hidden. Also, the brand names has been changed to something imaginative.
mapping_dict = {'brands_1036':'Aba',
'brands_0024':'Deald',
'brands_0016':'Jack D',
'brands_0023':'Tiger',
'brands_0003':'Maan',
'brands_0001':'Lurian',
'brands_1050':'Tapern'}
Now I can use this dictionary to map the brand codes in the column names:
df_map.columns = pd.Series(df_map.columns.tolist()).replace({'{':'', '}':'','Brands':'brands', '.slice':''}, regex=True).replace(mapping_dict, regex=True)
And here I map all the brand codes in the values of the columns:
for col in df_map.columns:
if df_map[col].dtype == object:
df_map[col] = df_map[col].replace(mapping_dict, regex=True)
Since the mapping dictionary was created with underscores in the brand codes as they are recorded in the data set (eg. brands_0024), I had to wait with removing these until now:
df_map.replace({'_':''}, regex=True, inplace=True)
For mapping all the answers that were based on a scale of some sort, and not just a brand, a dictionary was created for each “topic”. For example all the questions related to “familiarity_time” had to be mapped like this:
familiarity_time = {'1':'I buy this brand most often',
'2':'I buy this brand regularly',
'3':'I’ve bought this brand in the past 3 months',
'4':'I’ve bought this brand longer ago',
'5':'I’ve seen or heard about it but never tried it',
'6':'I’ve never seen or heard of it before today'}
And all the question relating to “consideration like this:
consideration = {'1':'My first choice',
'2':'Would seriously consider',
'3':'Might consider',
'4':'Would not consider'}
There were about 10 different areas in total.
Finally I can loop over all the columns and different topics and map the values accordingly:
topics = ['familiarity_time', 'consideration', 'unique', 'meets_needs', 'innovative', 'esteem', 'priceworth', 'tbca', 'hhsize', 'income', 'region', 'chief', 'cat_usage', 'hhcomp']
for col in df_map.columns:
for topic in topics:
if topic == 'hhcomp' and topic in col.lower():
df_map[col] = (df_map[col].str.replace('1', '1x')
.str.replace('2', '2x')
.str.replace('3', '3x')
.str.replace('4', '4x')
.str.replace('5', '5x')
.str.replace('998', '6x')
.str.replace('1x', 'Adults 18 and over')
.str.replace('2x', 'Teenagers 13 to 17')
.str.replace('3x', 'Children 10 to 12')
.str.replace('4x', 'Children 6 to 9')
.str.replace('5x', 'Children under 6')
.str.replace('6x', 'Do not wish to answer')
)
elif topic != 'hhcomp' and topic in col.lower():
df_map[col] = df_map[col].map(eval(topic)).fillna(df_map[col])
else:
continue
The ‘hhcomp’ coloumn was able to have more than one answer seperated with a ‘,’:
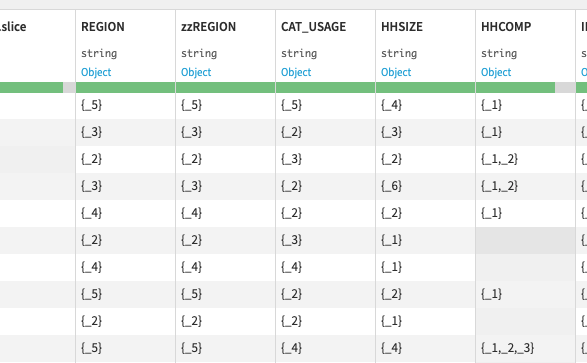
Since the answers also had numbers in them, it was not straight forward to replace the values. I decided to replace 1 with 1x, 2 with 2x etc. so there would be no issues when replacing 3 with ‘Children 10 to 12’ for example. Because, then the ‘3’ in ‘Teenagers 13 to 17’ would have also been replaced.
The rest of the columns were straight forward in mapping based on the different dictionaries that was created, as can be seen in the “elif” part of the loop.
Below is a screenshot of the final data set where everything is mapped: